

PROMETHEUS: INDUCING FINE-GRAINEDEVALUATION CAPABILITY IN LANGUAGE MODELS
FLASK 논문을 쓴 연구진들이 후속(?) 논문으로 작성한 Fine-grained LLM Evaluator 논문으로 ICLR 2024에 accept 되었습니다.
GPT-4와 같은 priority LLM을 생성된 텍스트에 대한 평가자로 쓰는 것은 다음과 같은 한계가 있음
- Closed-Source 생태계 : 공정하지 못할 수 있고, 중립성과 자율성 부족
- Uncontrolled visioning : 버전이 바뀌면 생성 결과를 재현하기 어려움
- prohibited costs : 가격 문제
따라서 연구진들은 오픈 소스, 재현 가능, 운용이 비싸지 않은 13B 프로메테우스 언어모델을 공개함
Feedback Collection 데이터셋
프로메테우스 모델은 LLaMA-2-chat 13B 모델을 Feedback Collection 데이터셋으로 파인튜닝한 모델임
데이터셋을 구축할 때 연구자들이 신경 쓴 것은 다음의 4가지이다
1. 최대한 많은 레퍼런스를 데이터셋에 포함시킬 것
2. 답변 길이에 따라 점수가 편향되는것을 방지하기위해 데이터셋에 포함되는 답변의 길이를 통제함
3. 데이터셋 내에 포함되는 점수의 분포를 균일하게 함
4. 지침과 대응의 범위를 사용자가 LLM과 상호작용하는 현실적인 상황으로 제한함
데이터셋의 입력 부분
- 인스트럭션 : LLM에게 입력되는 프롬프트
- 평가해야 할 응답 : 인스트럭션에 대한 응답
- 점수에 대한 기준 : 평가 기준 + 1~5점을 주는 기준 두 가지로 구성되어 있음
- 레퍼런스 응답 : 5점을 받는 응답의 예시
데이터셋의 출력 부분
- 피드백 : 응답이 왜 해당 점수를 받아야 하는지에 대한 근거(rationale). CoT와 유사한 형식을 띠고 있음
- 점수 : 1~5 사이의 정수 점수
데이터셋 구축 과정
1. Seed Rubric(시드 평가기준) 제작
: 사람이 직접 fine-grained 평가기준을 50개 제작함
2. gpt-4를 통한 증강
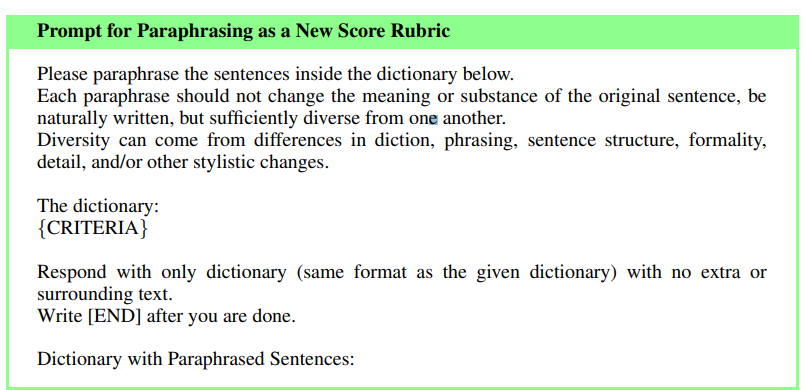
시드 평가기준을 gpt-4를 통해 강건하고 다양한 1000개의 평가 기준으로 증강함 (In-Context-Learning 사용)
먼저 새로운 기준을 여러 개 만들고(brainstorming), 그것을 다시 의역(paraphrasing)해서 합치는 식으로 모델이 일반화할 수 있도록 함
총 1000개의 기준을 만듦
3. 기준에 부합하는 인스트럭션 제작
: gpt-4에게 평가 기준과 연관성 있는 인스트럭션을 제작하도록 해 총 2만개(각 기준당 20개) 제작함
4. 점수에 맞는 응답 예시 제작
: gpt-4에게 평가 기준의 각 점수에 부합하는 응답 예시를 생성하도록 함
결과적으로는 20개의 인스트럭션, 5개의 점수&피드백 조합을 가지고 있는 기준이 1000개로 데이터셋이 구성됨
Feedback Collection 데이터셋으로 llama-2-chat 7b와 13b를 훈련시켜 프로메테우스 모델을 만듦
(현재 허깅페이스에 MoE 8*7B도 올라와있음)
성능
성능을 측정하기 위해 데이터셋과 동일한 구조로 이루어진 Feedback Bench(데이터셋에 있는 seen 1000개, 없는 unseen 50개 중 unseen 만 사용)를 제작하였음
거기에 더해 vicuna-bench와 mt-bench에서 각각 80개 프롬프트 추출해서 각 프롬프트에 맞는 기준 제작해서 사용하고,
기존 flask 데이터셋에서 200개 프롬프트 추출하여 사용했음
또한, 단순한 점수를 매기는 언어 모델이 아닌 rewarding model로써의 사용 가능성도 가늠하기 위해 HHH alignment나 MT Bench Judgement와 같은 데이터셋에서도 실험을 진행함
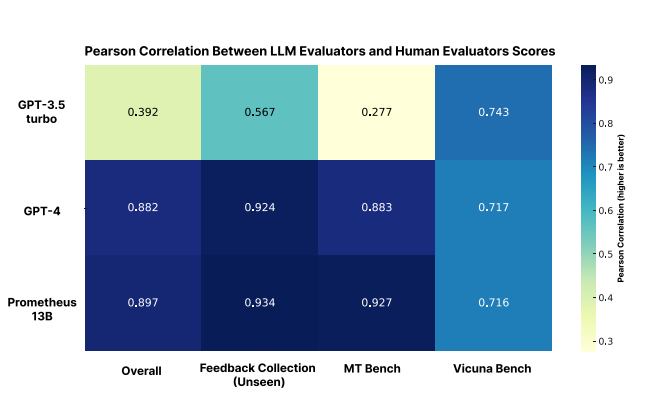
인간이 매긴 평가 결과와의 피어슨 상관계수가 gpt-4와 동등한 수준임
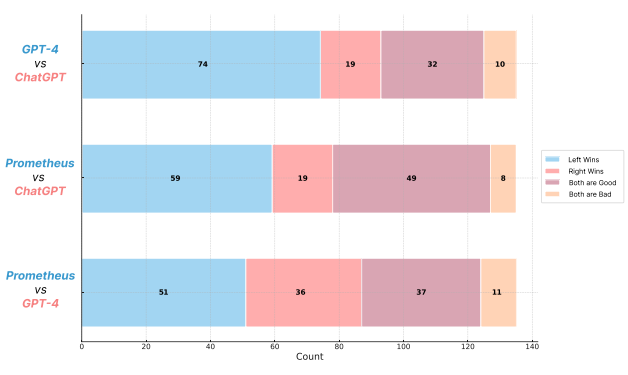
평가 피드백 퀄리티에 대한 win-rate 또한 gpt-4를 상회함
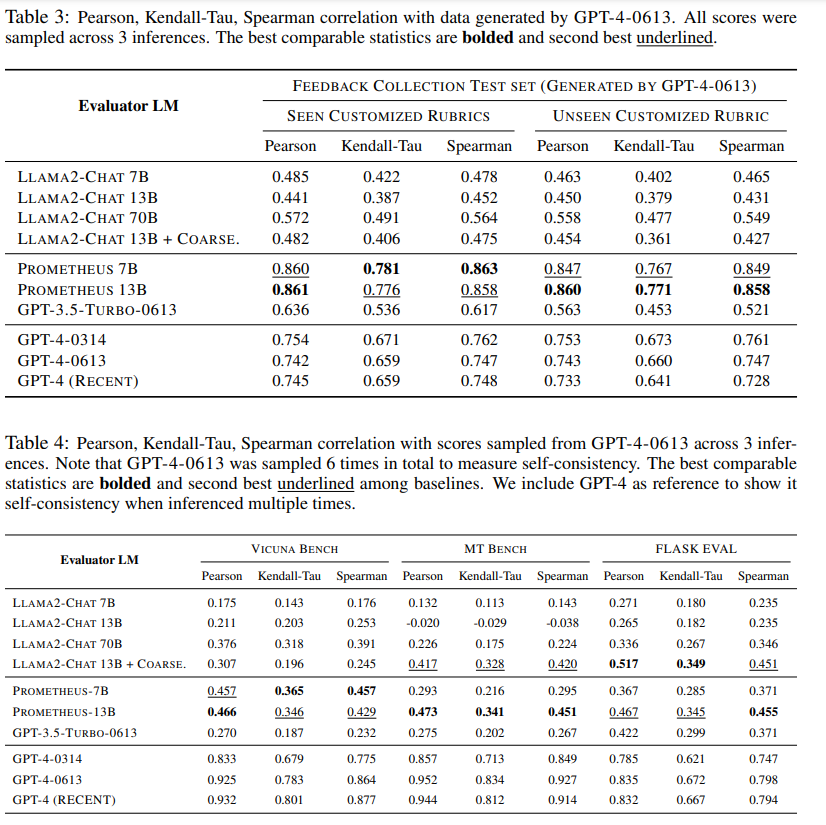
각 벤치에 관해 gpt-4가 평가한 점수와 프로메테우스가 평가한 점수의 상관계수
llama-2 coarse 모델은 FLASK 데이터셋의 일부만 샘플링해서 파인튜닝한 llama-2 모델임
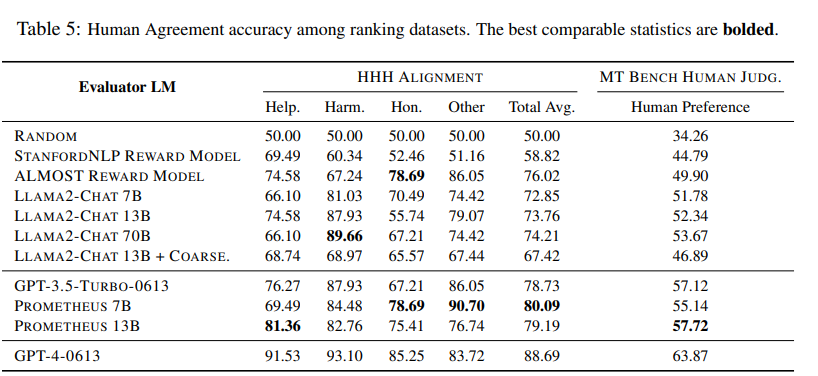
RLHF에 활용될 수 있는 ranking grading scheme 데이터셋에서도 괜찮은 성능을 보임
-> 이것을 위한 데이터로 튜닝되지 않았음에도 이런 성능을 보이는것에 주목