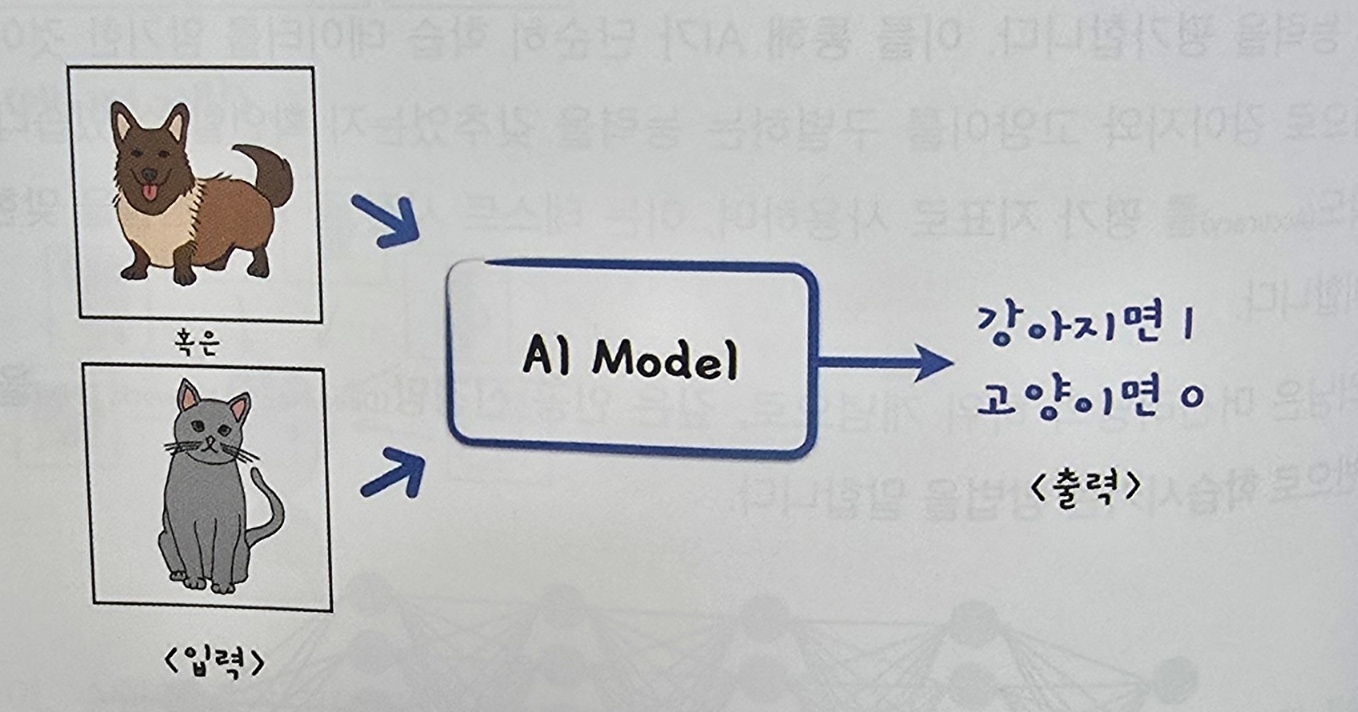
들어가며 LLM 과 에이전트의 시대로 접어든 지금일수록( DeepSeek로 인해 다시금 점화되었죠.), 이론에 대한 원리를 더 확실히 알고 있는 것이 중요하다고 생각합니다. 단순히 AI 툴을 사용하는 '소비자' 가 아니라 AI 개발을 하고, 제품과 서비스를 만드는 '생산자'의 입장에 계신 분들이라고 한다면 더더욱 그렇습니다. 이번에 좋은 기회로 혁펜하임님이 출판하신 딥러닝 책 을 제공받아 리뷰를 할 수 있게 되었습니다. 본 리뷰에서는 크게 두 가지 관점에서 이 책을 추천드리는 이유를 말씀드리겠습니다. 추천드리는 이유 1. AI를 쉽게 설명할 필요가 있을 때 AI 관련해서 일을 하다 보면, 관련 직종이 아닌 사람들로부터 흔히 이런 질문을 받곤 합니다. '인공지능(딥러닝)이 뭐야?', '그게 그렇게 ..