

Abstract
- 28개의 LLM을 사용해 사전 학습 데이터 설계의 영향을 조사
- 데이터의 시간적 관련성(curated at different times), 품질(quality) 및 유해성(toxicity) 필터링, 그리고 다양한 도메인 구성(domain composition)이 모델 성능에 미치는 영향을 분석
실험에 사용된 모델 & 데이터셋
- C4(2020)
Common Crawl의 정제 버전, 다양한 웹 문서를 포함하며 영어 텍스트로 필터링되어 있고, 많은 언어 모델 훈련에 널리 사용되는 오픈소스 데이터셋
- The Pile
22개 출처의 데이터로 구성된 800GB 데이터셋 웹 스크랩과 다양한 분야의 텍스트를 포함

데이터 평가 척도
- 데이터셋의 나이

Pile에는 시간 데이터가 없어서 분석 불가능
- 도메인 필터링

Pile은 다양한 데이터 출처가 명시되어 있음
- 내용 필터링
- Common Crawl과 같은 인터넷 소스에서 파생된 데이터셋은 저품질, 유해, 공격적 콘텐츠를 포함하므로 필터링이 필요함
- 문서의 적절성을 판단하는 방법으로는 단순 특성 기반 필터, 부정적 정의 필터, 긍정적 정의 필터 등이 있음
- 본 연구에서는 최신 언어 모델 개발에 널리 사용되는 두 가지 분류기 기반 필터(유해 콘텐츠 제거, 고품질 콘텐츠 유지)의 영향을 평가함
- 품질 필터링
- 본 연구에서는 PaLM과 GLaM에서 사용된 분류기를 활용하여 0(고품질)에서 1(저품질) 사이의 점수를 문서에 부여함
- 유해성 필터링
- 유해 콘텐츠 식별을 위해 Jigsaw의 Perspective API를 사용
- 이 API는 온라인 포럼 댓글을 기반으로 훈련되어 0(유해 가능성 낮음)에서 1(유해 가능성 높음) 사이의 점수를 부여
- 연구에서는 다양한 독성 임계값(0.95, 0.9, 0.7, 0.5, 0.3)을 적용하여 문서를 필터링하고, 원본 C4 데이터셋에서 사용된 n-gram 기반 필터도 실험함
성능 평가 척도
- 도메인 일반화
- MRQA, UnifiedQA
- 시간에 따른 불일치 (misalignment) 평가
- 미세조정과 평가 시점 사이의 시간 간격이 증가할수록 테스트 성능이 저하된다는 연구 결과 있음
- PubCLS, NewSum, PoliAffs, TwiERC, AIC 데이터셋으로 평가
- 유해적인 생성 평가
- Perspective API로 생성된 텍스트의 독성 점수를 측정하고, RealToxicityPrompts 데이터셋도 활용하여 평가함
- 유해적 텍스트 인식 평가
- Social Bias Frames, DynaHate, Toxigen 등의 데이터셋을 사용함
Impact of Data Curation on Data Characteristics
-> C4랑 Pile 비교하는 부분인데 생략
Impact of Dataset Age on Pretrained Models
- 모델과 평가 데이터셋 모두 시간이 지나면 낡아질 수 있음
- 사전학습 데이터와 평가 데이터 간의 시간적 불일치는 미세조정으로 해결되지 않음
- 시간적 불일치로 인해 서로 다른 시기에 학습된 모델들의 평가가 복잡해짐


- 시간적 성능 저하는 작은 모델보다 큰 모델에서 더 두드러지게 나타남, 이는 큰 모델이 시간적 정보에 더 민감할 수 있음을 시사함
Impact of Quality & Toxicity Filters on Pretrained Models
- 품질 필터와 독성 필터는 매우 다른 효과를 보임
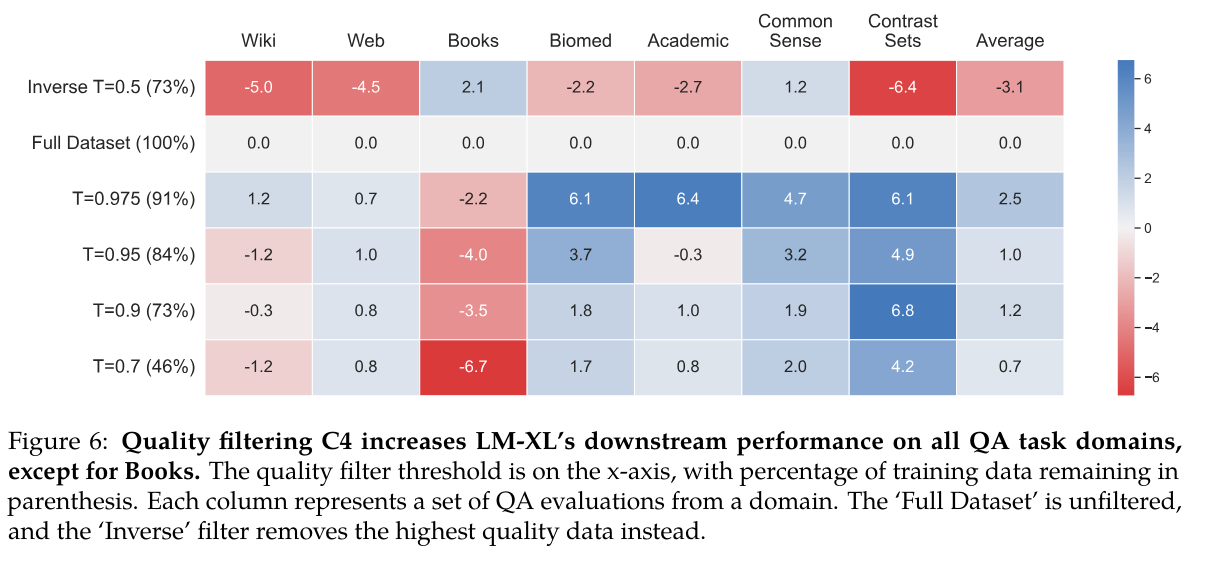

- 품질 필터는 훈련 데이터를 줄임에도 성능을 크게 향상시킴
- 품질 필터링의 효과는 데이터셋 특성만으로 쉽게 예측되지 않음
- 도메인에 따라 다른 품질 필터를 적용해야 함 (어떤 데이터셋의 경우 역 필터가 가장 좋은 효과를 보임)
- 독성 필터링은 일반화 능력과 독성 식별 능력을 희생하여 유해한 텍스트 생성 위험을 줄임
Impact of Domain Composition on Pretrained Models
- 다양한 데이터 소스를 포함시키는 것이 데이터 품질이나 크기보다 더 중요
- 특정 데이터는 특정 평가에 도움이 되지만, 항상 이질적인 웹 도메인의 포함만큼 도움이 되지는 않음
- 가능한 한 많은 사전 학습 데이터 소스를 포함하는 것이 좋음

Discussion
- 데이터셋은 크고, 다양하며, 고품질이어야 함
- 사전 훈련 큐레이션의 선택은 모델에 큰 영향을 미침
- 후속 미세 조정으로 이러한 영향을 쉽게 지울 수 없음
- 모델은 최신 데이터로 지속적으로 재훈련되어야 함
- 새로운 데이터에 대한 미세 조정이 환각 문제를 악화시킬 수 있음(schulman, 2023)
- 사전 훈련에서 다루지 않은 정보로 모델을 미세 조정할 때의 잠재적 부작용을 인식해야 함
- Book(전반적으로 높은 품질) 제외하고 품질 필터링이 데이터 수를 줄임에도 불구하고 항상 높은 효과를 보임
- 작업/도메인의 성능은 단순히 저품질 데이터를 얼마나 제거했느냐에만 영향을 받는 것이 아님
- 최고 또는 중간 품질의 데이터가 특정 측정 차원에서 얼마나 많이 대표되는지도 중요한 요소