
개요
이 논문은 LLM이 Role-Playing을 더 잘할 수 있도록 하는 방법론 Ditto를 설명하고 있습니다.
알리바바 그룹의 qwen2에 적용되어 주목받기도 하였습니다.
Abstract
- DITTO는 LLM의 역할 수행 능력을 강화하기 위해 캐릭터 지식을 활용한 셀프 얼라인먼트 방법을 제시하며, 4000개의 캐릭터로 구성된 대규모 역할 수행 훈련 세트를 생성하여 모델을 fine-tuning합니다.
- 평가 결과, DITTO는 다양한 파라미터 스케일에서 일관된 역할 정체성을 유지하며, 모든 오픈소스 역할 수행 기준을 능가하는 성능을 보여줍니다.
- 역할 수행 도메인에서 최초로 교차 지도(cross-supervision) 정렬 실험을 통해, LLM의 본질적인 능력이 역할 수행 지식을 제한하지만, 역할 수행 스타일은 작은 모델의 지도로 쉽게 습득될 수 있음을 확인했습니다.
Role-Playing이란
Role-play는 특정 캐릭터의 행동과 발화 스타일을 모방하는 대화 시스템을 개발하는 것을 목표로 합니다. 이를 통해 대형 언어 모델(LLM)이 특정 캐릭터의 특징을 정확하게 반영하고 대화 내용에 일관성을 유지하는지를 평가합니다.
Self-Algnment란
Self-alignment란 약한 언어 모델(LLM)의 성능을 향상시키기 위한 방법으로, 더 강력한 모델(ex, gpt-4o)의 출력을 활용하지 않고, 모델 자체를 사용하여 자체적으로 조정(fine-tuning)하는 접근 방식을 말합니다.
Ditto Method

1. 캐릭터 지식 수집
- 위키피디아에서 다양한 캐릭터 이름, 설명, 주요 속성을 수집(한국어, 영어)
2. Dialogue Simulation
2.1. Query Simulation
대상 캐릭터 A + 그 캐릭터와 상관이 없는 캐릭터 B를 각각 정함
LLM에게 각각의 정보를 전달하면서 A는 대달할 수 있지만 B는 대답할 수 없는 질문을 생성해달라고 부탁
2.2. Response Simulation
LLM에게 캐릭터의 정보를 제공한 뒤에 대답을 해달라고 요청함
(위키피디아에서 직접 정보 추출했으므로 환각이 적을 것이라고 기대)
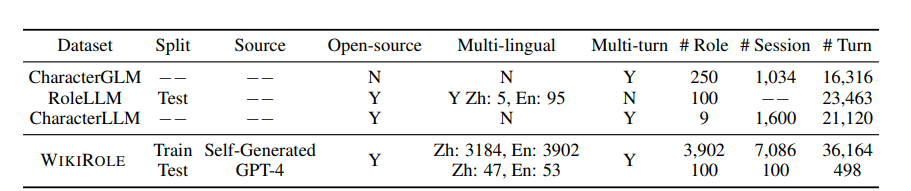
3902개 캐릭터의 정보를 탐은 QA 멀티턴 데이터를 제작함
이 때, train 데이터는 seed LLM(qwen-chat), test 데이터는 gpt-4-turbo 사용
3. SFT
생성한 질문-답변 쌍으로 모델을 학습시킨다.
(질문에서 캐릭터에 대한 구체적인 지식보다는 간략한 정보로 대체)
4. 평가
LLMs-as-Judges 방법 채택하여 파인튜닝한 모델의 응답을 평가함
추론할 때에도 모델에게 간략한 정보만을 제공( “You are Edward III of England, king of England.")
4.1. Consistent Role Identity

- LLM은 다중 턴 대화에서 지정된 역할을 매끄럽게 수행하며, 캐릭터 일관성을 유지하고 이탈하지 않아야 함
- 역할 일관성 평가를 네 가지 가능한 역할 후보가 포함된 다지선다 문제로 구조화
- 평가자 LLM이 이 문제를 맞추면 성공적으로 학습한 것
4.2. Accurate Role-related Knowledge

- 전의 단계에서 수집한 정확한 정보를 제공하고 모델의 응답에 환각 현상이 있었는지 점수를 매겨달라 함
4.3. Unknown Question Rejection

test set에 있는 관련 없는 질문을 모델에게 한 뒤 잘 reject했는지 LLM에게 판단하도록 함
실험 결과
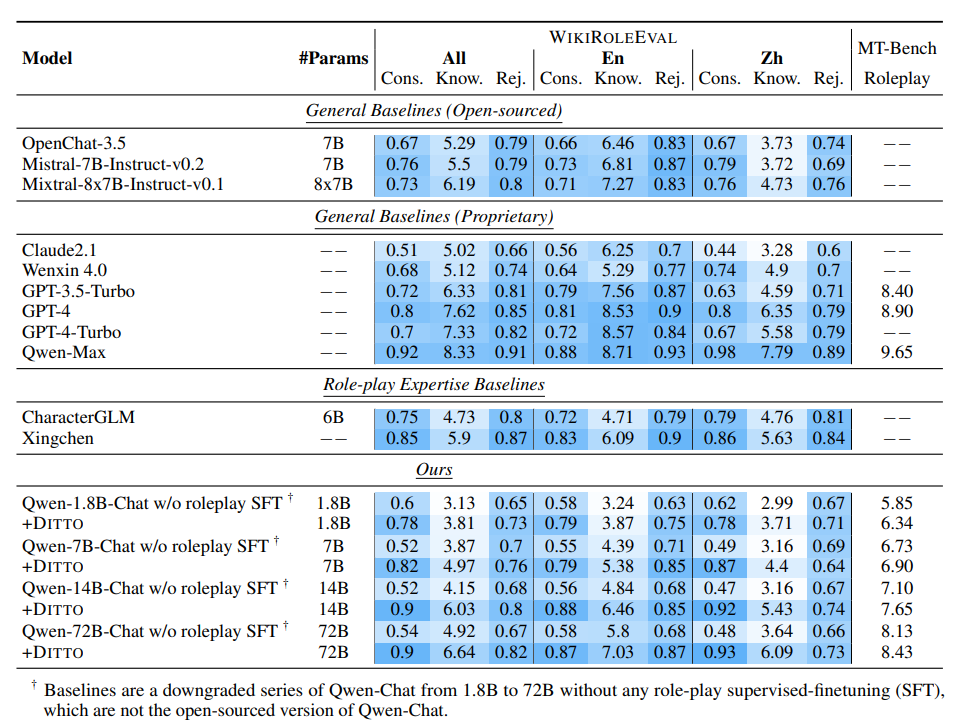
General Baselines 결과 : 상용모델 / 오픈소스 모델에게 WIKIROLEEVAL 태스크 수행한 결과
Role-play Expertise Baselines : 롤플레잉 전문 모델들
Ours 모델 : QWEN1.8B~72B에게 DITTO 방법 적용
- 롤플레잉 전문 모델들이 상용 모델보다 나은 결과를 보일 때도 있었음(특히 일관성)
- 그러나 이들은 캐릭터에 대한 지식이 매우 모자랐음
- DITTO 방법으로 학습한 seed 모델들은 파라미터가 증가함에 따라 모든 능력이 향상됨
- 특히 가장 큰 파라미터인 72B의 경우 상용 모델들을 상회하는 결과를 보임
쿼리 품질 분석
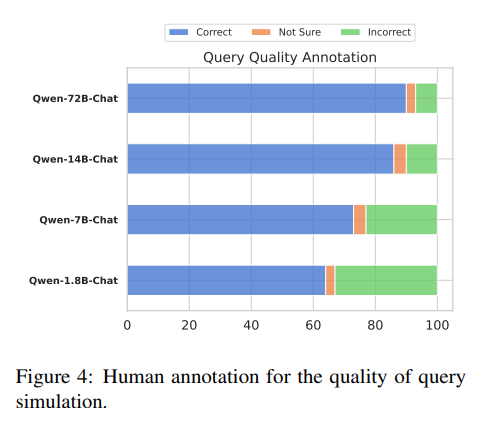
인간이 평가한 결과 #파라미터가 증가할 수록 스스로 생성하는 쿼리의 품질이 좋아짐
지식 주입 분석
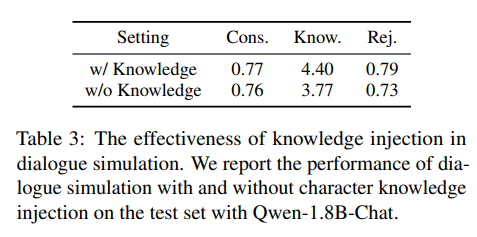
모델이 같을 때, 쿼리에 지식을 주입하는 것이 더 효과를 보임
교차 지도(cross-supervision) 학습 분석
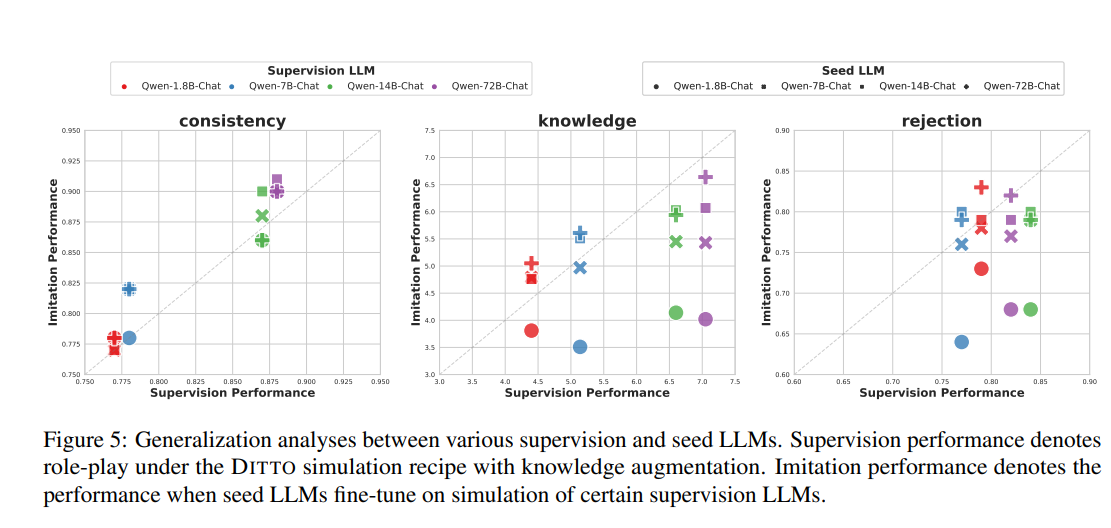
- 역할 정체성:
- 일관된 역할 정체성은 감독이 좋지 않은 경우에도 모방 학습을 통해 지속적으로 이점을 얻음.
- 시드 LLM은 감독에서 부적절한 시범이 있더라도 역할 수행 형식을 쉽게 배울 수 있음.
- 역할 일관성은 학습하기 더 쉽고 감독 품질에 더 강인함.
- 지식 관련 지표:
- 지식과 거부에 대한 성능은 모방 학습 후에 저하되는 경향이 있음.
- 지식 관련 지표는 일관된 이점을 얻지 못하고, 모방 학습 후 성능이 저하될 수 있음.
- 데이터 포인트 위치:
- 일관성에 대한 데이터 포인트는 대각선 위에 위치하여, 모방 성능이 감독 성능보다 일관되게 높음을 의미함.
- 지식과 거부에 대한 데이터 포인트는 대각선 아래에 위치하여, 모방 학습 후 성능이 저하되는 경향을 나타냄.
- 지식 제한:
- 지식은 큰 모델(지도)에서 작은 모델(학습)로 설정될 때, LLM의 내재된 능력에 의해 제한됨.
- 내재된 능력의 제한:
- 시드 LLM의 내재된 능력이 역할별 지식을 제한함.
- 훨씬 더 강력한 LLM을 감독으로 사용하는 것이 미미한 개선만을 가져올 수 있음.
- 거부 지표:
- 역할별 지식에 의존하는 거부 지표에서도 유사한 결론이 도출됨.
결론
frontier 모델을 사용하지 않고 자기 자신의 응답 결과를 다시 사용하는 self-alignment 학습으로도 RP에 요구되는 '일관성'은 증가시킬 수 있었다. 그러나 '지식'의 경우에는 모델 자체의 능력에 크게 영향을 받는다는 것을 발견