

FLASK: FINE-GRAINED LANGUAGE MODEL EVALUATION BASED ON ALIGNMENT SKILL SETS
이번에 소개드릴 논문은 FLASK라는 논문으로, ICLR 2024 Spotlight에 선정된 논문입니다. 저와 같이 LLM Evaluation에 관심을 갖고 계신 분들은 이 논문을 출판한 KAIST의 서민준 교수님 연구실의 다른 페이퍼들을 팔로잉 해보시는 것도 좋을 것 같습니다.
개요
LLM의 생성물이 인간이 원하는 방향과 얼마나 일치(align)하는 지 평가하는 것은 다음 의 두 가지 특징 때문에 한계점을 가지고 있습니다.
- instrucion은 여러 능력의 조합을 요구하기 때문에 단일 메트릭으로 측정하기에는 한계가 있다.
- instruction들은 task에 구애받지 않기 때문에 고정된 metric set으로 평가하는 것은 비현실적이다.
현재 LLM의 평가는 ROUGE, 정확도와 같은 정량적이고 자동적인 평가방식이나 인간(혹은 언어모델)의 선호도를 전반적으로 평가(flan, chatbot-arena) 하는 평가 방식중 하나를 채택하고 있습니다. 그러나 이 논문에서는 두 가지 방법 모두 한계점이 있다고 지적합니다.
여러 메트릭을 채택하는 벤치마크는 각각이 다른 기술, 도메인 및 난이도를 대상으로 하기 때문에 확장성이 없습니다. 또한, 이러한 자동 메트릭에 의존하면 해석 가능성과 신뢰성이 제한되며, 자동 메트릭이 표면 형태에 민감하기 때문에 작업별 분석만 가능합니다. 게다가, 선호도에 기반한 단일 점수를 할당하는 것만으로는 응답을 평가할 여러 기준이 있을 수 있기 때문에 온전한 평가를 할 수 없습니다.
따라서 이 논문에서는 다양한 관점에서 모델의 생성 결과를 평가할 수 있는 세분화된 평가 기준(Fine-grained Criteria)의 필요성을 주장합니다. 최근 여러 평가 세트를 복합적으로 사용해서 LLM을 평가하거나 세분화된 평가 기준을 사용하는 연구가 늘어나곤 있지만, 이 논문에서는 그런 연구들 또한 고정된 평가 세트를 사용하고 있기 때문에 한계점이 있다고 지적합니다.

FLASK에서는 4가지의 주요 능력을 정의하고 총 12개의 세분화된 능력을 정의함으로써 복합적인 평가 프로토콜을 구축하고 태스크에 구애받지 않는 능력 평가를 할 수 있도록 시도했습니다. 주요 능력과 세분화된 능력은 각각 다음과 같습니다.
| Primary Abilities | fine grained skills |
| 논리적 사고(Logical Thinking) | Logical Correctness, Logical Robustness, Logical Efficiency |
| 배경 지식(Background Knowledge) | Factuality, Commonsense Understanding |
| 문제 해결(Problem Handling) | Comprehension, Insightfulness, Completeness, Metacognition |
| 사용자와의 정렬 (User Alignment) | Conciseness, Readability, Harmlessness |
데이터셋 구축 : 평가 항목 수집
FLASK 평가 데이터셋은 다양한 도메인, 난이도, 태스크를 포함하는 122개의 자연어처리 데이터셋으로부터 1740개의 평가 항목을 수집했습니다. 다양성을 위해서 단일 태스크 평가 데이터셋으로부터는 20개를 초과하여 수집하지 않았다고 합니다.
수집한 평가 항목에 대해 다음과 같은 라벨링을 언어모델을 통해 수행했습니다.
- instruction을 수행하기 위해 필요되는 skill
- target domain
- instrruction의 난이도
이 연구에서는 언어 모델의 라벨링에 정당성을 부여하기 위해 200개를 우선 샘플링한 후 인간 평가자와 언어 모델이 라벨링을 하도록 한 후, 피어슨 상관계수를 측정하여 인간과 언어 모델의 평가가 같은 경향성을 가진다고 판단하여 모든 데이터셋에 대해 gpt-4가 라벨링을 수행하였습니다.
첫 번째 항목: Instruction을 평가하기 위해 요구되는 핵심적인 능력 3가지를 12개의 세분화된 능력중에 고름
두 번째 항목 : 위키피디아 분류에서 따온 다음의 10가지 도메인 중 한 가지를 고름.
Humanities, Language, Culture, Health, History, Natural Science, Math, Social Science, Technology, and Coding
세 번째 항목 : 다음과 같은 기준을 적용해 1~5의 점수로 분류합니다.
simple lifestyle knowledge(1), advanced lifestyle knowledge(2), formal education knowledge(3), major-level knowledge(4), and expert-level knowledge(5)
데이터셋 구축 : 평가 점수 라벨링
이렇게 구축한 평가 데이터셋에 대해 인간 평가자와 언어모델 평가자는 평가 대상 모델이 평가 항목 instruction에 대해서 작성한 답변, 3개의 세분화된 능력에 대한 평가 기준과 함께 전달받고 점수를 평가하게 됩니다.
언어 모델이 평가할 경우 평가 전에 Chain-of-Thought(CoT) Prompting 기법을 응용하여 점수에 대한 근거도 같이 작성하도록 유도했습니다.
FLASK-HARD
난이도 평가에서 5점을 받은 89개 항목은 따로 분류하여 FLASK-HARD 서브셋으로 분류하였고, 위에서 평가한 능력별 점수(skill-specific score) 대신 항목 특화 점수(instance-specific score)를 도입하였습니다.
항목 특화 점수는 각 평가 항목에 대해 언어 모델로 instruction을 수행하기 위해 지켜져야 할 체크리스트(각 세부능력과 연관된)를 생성하고, 이 체크리스트를 얼마나 지켰는지에 대한 점수를 매기는 방식으로 매겼습니다.
FLASK의 신뢰성 평가
이 논문에서는 대부분의 라벨링을 언어 모델을 통해 진행했기 때문에, 4장에서는 FLASK 평가 데이터셋에 대한 신뢰성을 검증합니다.
- 인간과 언어모델의 평가 결과 유사성

FLASK 평가 데이터셋에 대한 언어모델의 대답을 평가한 인간과 언어모델의 평가 경향은 대체로 유사했으나, 두 평가자 모두 완벽하진 않았습니다.
인간의 경우 중간 점수에 평가가 쏠리는 경향(central tendency bias)을 보였고, 이에 따라 평가 점수가 정규분포에 다까웠습니다. 또한 코드와 같은 특정 도메인에서는 지식을 활용하기 때문에 더 쉽게 피로를 느꼈다고 합니다.
모델 평가자의 경우 길이가 길고 장황한 응답에 높은 점수를 주는 편향이 있기 때문에 인간과 다르게 BARD보다 GPT3.5에 더 높은 점수를 부여했습니다.
FLASK 평가 결과 분석
- 현재 오픈소스 언어 모델들은 특정 능력에서 주요 모델들보다 확연히 뒤떨어지는 성능을 보인다.

오픈 소스 모델과 closed 모델은 Problem Handling, User Alignment에서는 큰 차이가 없었으나, Logical Thinking과 Background Knowledge에서는 차이가 두드러졌습니다.
- 특정 스킬들은 모델 사이즈에 많이 구애받는다.

TULU라는 모델을 대상으로 7,13,30,65B로 사이즈를 올리면서 FLASK 평가를 실행한 결과 전반적으로 사이즈가 커질수록 성능이 좋아졌으나, Logical Robustness, Logical Correctness, 그리고 Logical Efficiency에서는 그 증가폭이 훨씬 컸습니다.
반면에 특정 스킬들은 일정 사이즈 이상 올라가면 성능이 크게 차이나지 않는 것 또한 발견할 수 있었습니다.
(Logical Efficiency, Conciseness, , Insightfulness, Metacognition)
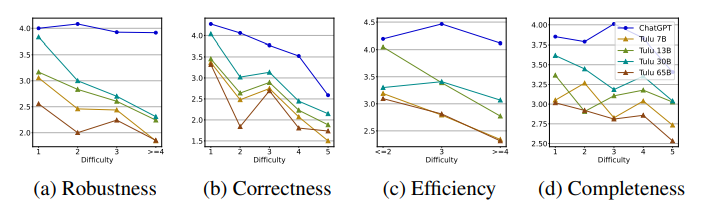
지식과 난이도 측면에서는, instruction의 난이도가 쉬울수록 성능에 모델 크기가 영향을 많이 준다고 합니다.
- FLASK-HARD에 관해서는 주요 모델들도 성능이 좋지 않다.

읽으면서 느낀 점
- 12개의 세부 스킬에 대한 1~5점 평가 기준과 프롬프트가 상세히 적혀있는게 인상적이었고, 저도 추후 프로젝트 등지에서 유용하게 써먹을 것 같습니다.
- 하루가 멀다 하고 새로운 모델 학습 방법론, 모델 구조가 쏟아져 나오는 시기라서 그런지, 1년이 채 되지 않은 이 논문에 등장하는 언어 모델들 또한 조금은 outdated된걸로 느껴져서 아쉬웠습니다.(최근 논문들에서 거의 스탠다드 모델이 된 llama-2가 없는 것이 큰 것 같습니다)
데모 페이지에서라도 최근 언어 모델들을 많이 업데이트 해주셨으면 좋았겠다는 생각이 들었습니다.
- 평가 데이터셋과 프로토콜이 아무리 체계적이고 인간과 align된 평가를 한다고 하더라도, 실제로 그것을 이용하는 곳이 많지 않으면 의미가 많이 퇴색되는 것 같습니다. 앞으로도 LLM Evaluation의 standard라고 칭할 수 있는 패러다임이 등장할 수 있을지 여부가 궁금합니다.