

- ChatGPT와 유사한 성능이 나오는 최초의 7B 언어모델
- 다양한 벤치마크에서 오픈소스 언어 모델 중 1위 기록중
OpenChat 소개

최근 LLM을 파인튜닝하는 방법론에는 SFT(Supervised Fine-Tuning)과 RLFT(Reinforcement Fine-Tuning)이 있는데, SFT는 데이터의 품질을 보장할 수 없다는 단점, RLFT에는 데이터를 구축하는 데에 비용이 많이 들어간다는 단점이 존재한다. OpenChat은 이러한 단점을 극복하기 위해 데이터 소스에 따라 강화학습 보상을 다르게 부여하는 C(onditioned)-RLFT 방법론을 제시한다. OpenChat13B 모델은 오픈 소스 13B 모델 중에서 가장 좋은 성능을 보였다.
SFT와 RLFT
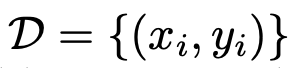
인스트럭션 xi와 응답 yi로 구성된 대화 데이터셋

사전학습된 언어 모델
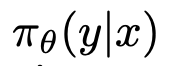
파인튜닝된 언어 모델
Supervised Fine-Tuning(SFT)

SFT는 대화 데이터셋을 MLE와 같은 지도학습으로 파인튜닝하는 기법이다. 파인튜닝한 모델이 높은 성능을 내기 위해서는 데이터셋 D가 굉장히 높은 품질을 가져야 하는데, 이는 SFT 방법에서는 데이터셋의 모든 데이터를 동등하게(uniformly) 다루기 때문이다. 그러나 SFT를 하기 위한 품질 높은 데이터셋을 구축하는 것은 굉장히 비용이 많이 드는 일이다. 따라서 현존하는 대부분의 오픈 소스 LLM들은 비용 문제로 인해 품질을 보장할 수 없는 데이터로 이루어진 대화 데이터를 파인튜닝에 사용한다. 이는 필연적으로 생성 결과물의 품질 하락으로 이루어질 수 밖에 없다.
Reinforcement Learning Fine-Tuning(RLFT)
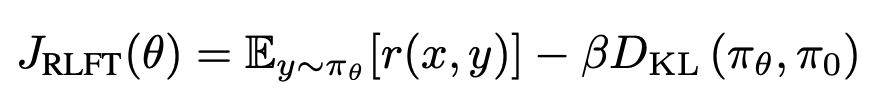
RLFT는 인간 피드백이나 사전에 정의된 classifiers에 따라서 보상을 부여하는 구조로, 이 보상을 최대화하는 식으로 LLM을 파인튜닝한다. 보상 r(x,y)는 바람직한 반응에는 높은 값을, 나쁜 반응에는 낮은 값을 할당하며 파인튜닝된 LLM을 학습시킨다. 가장 많이 사용하는 강화학습을 활용한 LLM 파인튜닝 프레임워크는 KL-정규화 RL이다. 이는 파인 튜닝된 LLM에 KL 패널티를 부여하여 데이스 모델로부터 너무 멀어지지 않도록 한다. (수식에서 빼는 부분) 이는 강화학습의 보상을 최대화 하려나 원래 모델의 분표가 망가지는 (distribution collapse)일을 방지한다. RLFT에서 중요한 것은 높은 퀄리티의 보상 신호이다. 그러나 인간의 피드백을 모델을 학습시킬 수 있을 만큼 충분히 모으는 것은 비용이 많이 드는 일이고, 이는 오픈 소스 모델이 강화학습 기법을 학습에 도입하는 것을 망설이게 만든다.
OpenChat
OpenChat은 위에서 소개한 방법들의 한계점을 극복하기 위해 완성도가 높지 않은 (sub-optimal) 데이터셋과 높은 퀄리티/전문가에 의해 제작된 데이터셋 모두를 활용하여 파인튜닝할 수 있는 방법론을 사용하였다. 가장 유명한 SFT 데이터셋인 ShareGPT (vicuna를 학습시킬 때 사용됨)은 gpt-4와 gpt-3.5 두 가지 소스로부터 가져온 데이터로 구성되어 있는데, 각각 높은 퀄리티 데이터셋과 낮은 퀄리티 데이터셋으로 간주할 수 있다.
데이터의 퀄리티 차이만으로 정확한 보상 신호(fine-grained reward signals)를 주는 것은 불가능하지만, 내재적이거나(implicit) 약하고 거친 보상신호(coarse-grained reward imformation)로는 취급할 수 있다. 따라서 본 논문에서는 파인튜닝된 언어모델에 데이터 소스를 반영한 새로운 정규화 방법을 적용하는 것을 제안한다.
Class-Conditioned Dataset and Rewards
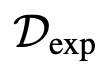
전문가 데이터셋

차선책 데이터셋

위의 두 데이터셋의 소스를 라벨링하여 새로운 데이터셋을 구축한다. 이 데이터셋으로 다음과 같은 거친 보상 신호를 인코딩 할 수 있다.

차선책 데이터에 대한 보상을 전문가 데이터셋에 대한 보상보다 낮게 설정함으로써 파닝튜닝한 모델이 높은 퀄리티의 응답에 가깝게 학습되도록 할 수 있다.
Fine-Tuning via C(onditioned)-RLFT
위의 식에서 부여하는 보상이 매우 거친 방식으로 책정되었기 때문에 추가적인 정보를 제공해야 한다. 오프라인 RL의 목표 조건 지도 학습에서 영감을 얻은 C-RLFT를 소개합니다. 이는 목표/결과 조건 정책에서 적절한 정보를 조건화함으로써 최적화된 성능을 복구할 수 있다. C-RLFT의 핵심은 2가지이다.
- LLM을 파인튜닝 할 때 class-condition 에 따라 하는 것
- RL 정규화 시 원래의 사전학습 모델 대신 클래스 정보를 답고 있는 모델을 사용하는 것
Class-conditioned policy
현존하는 방법으로 바로 파인튜닝하는 것 대신 다음과 같이 데이터들의 소스를 반영한 토큰을 삽입하는 방법을 사용함

여기에서 <|end.of.turn|> 토큰은 EOS 토큰과 유사한 기능을 하나, 사전학습 시 학습한 EOS 토큰과 모델이 착각하지 않도록 새로 추가한 것이다.
Policy optimization
C-RLFT에서는 거칠게 정제된(coarse-grained) 데이터 소스 보상 체계를 만들기 위해 위에서 설명했던 KL 정규화 강화학습 식에서 약간의 수정을 가했다.

위의 원본 KL Regularized RL 식과 다른 점은 사전학습 모델 자리에 class-conditioned 데이터셋으로 학습된 모델이 들어갔다는 점이다. 이와 같은 구조를 채택한 이유는 다음과 같다.
- 현존하는 대부분의 오픈 소스 사전학습 LLM들은 API 기반 모델들(gpt-4 등)에 비해 성능이 좋지 못하다. 이는 곧 gpt-3.5로부터 모은 D_sub 데이터조차 사전학습 모델보다 퀄리티가 높다는 것을 의미한다.
- class-conditioned 방법으로 학습한 모델은 데이터 소스에 관한 추가 정보를 담고 있어서 데이터의 퀄리티를 차별화 할 수 있다.
본 방법론의 목적함수는 다음과 같고, KL divergence의 값을 최소화하는 방향으로 학습된다.

이 목적함수는 정확한 보상 라벨링을 요구하지 않으며, 대신 모델의 생성물 결과의 좋고 나쁨을 구별하는 방법을 사용한다. 또한 사전학습된 모델을 사용하지 않음으로써 PPO를 사용하는 다른 강화학습 방법론들과 다르게 사전학습 모델을 로드할 필요가 없고, 그만큼 컴퓨팅 자원을 아낄 수 있다.
Model inference
높은 퀄리티의 결과물을 얻기 위해, 학습 시 사용했던 GPT-4 프롬프트를 추론 때에도 사용한다.

모델 실험
사용된 벤치마크
- AlpacaEval
- MT-bench
- Vicuna-bench
- AGIEval
베이스라인 모델
- gpt-4
- gpt-3.5
- claude
- llama-2-chat (SFT, RLHF)
- wizardlm, guanaco, ultralm, vicuna (SFT)
gpt에 의한 평가 벤치마크 실험

AlpacaEval, MT-bench, Vicuna-bench와 같은 벤치마크들은 gpt-4 나 alpaca_eval_gpt와 같은 언어 모델을 평가자로 사용하고, 인간 평가와 비교했을 때 신뢰성이 있다고 주장되었다. 평가 결과 같은 13B수준 모델들 중에서는 vicuna-bench를 제외한 2개의 벤치마크에서 가장 좋은 성능을 보였으며, 파라미터가 더 많은 모델들과도 경쟁할만한 결과를 보였다.

MT-bench 벤치마크 비교 결과 API 기반 언어 모델들보다는 떨어지지만 오픈 소스 언어 모델중에서는 가장 좋은 걸 확인할 수 있었다. (심지어 70B 모델보다도)
일반화 성능을 확인하기 위해 AGIEval 벤치마크 점수를 확인 결과 llama-2-13b보다 평균 점수가 더 높은 것을 확인할 수 있다. (다른 베이스라인 모델들은 그렇지 못함)
(mixed-quality data, ablation studies 생략)
Revealing secrets of C-RLFT

ablation studty에서 사용한 SFT 학습 방법만 사용한 openchat-13b와 C-RLFT를 적용한 원래 버전을 비교하기 위해 2000개의 gpt-4, gpt-3.5 대화를 무작위 선별해 임베딩을 추출했다. 그 후 UMAP 기법을 사용하여 차원축소 후 시각화 결과 두 가지 모델에서 모두 클러스터터가 어느정도 생성되어 있지만 SFT버전 모델의 임베딩은 대화 소스의 구분이 없는 반면 C-RLFT 버전은 데이터 소스에 따라 임베딩이 확연하게 다르게 나타나는 모습을 보인다.

추론 단계에서 사용한 class-conditioned prompt 를 바꾸어서 실험해본 결과 성능이 차이난다는것을 확인했다. 이는 곧 openchat 모델이 데이터의 다른 품질을 구분할 수 있으며 또한 gpt-4에서 얻은 데이터가 gpt-3.5에서 얻은 데이터보다 월등하다는 것 또한 의미한다.
'자연어처리' 카테고리의 다른 글
| [NLP]FLASK: FINE-GRAINED LANGUAGE MODELEVALUATION BASED ON ALIGNMENT SKILL SETS 논문 리뷰 (0) | 2024.03.25 |
|---|---|
| [NLP]MoE(Mixture of Experts)과 Mixtral 살펴보기 (1) | 2024.02.08 |
| [NLP]한국어 거대모델(LLM)들 소개 (23년 5월) (2) | 2023.05.04 |
| [Hugging Face] PEFT에 대해 알아보자 (3) | 2023.02.16 |
| [NLP] Lexical Simplification(어휘 단순화) (0) | 2023.02.11 |