
MoE(Mixture of Experts)는 최근 DPO, DUS 등과 더불어 주목받고 있는 LLM의 성능을 높이기 위해 사용되는 방법론 중 하나입니다.
23년 12월에 Mixtral 8x7B가 공개되었고, 이 모델이 llama2-70B를 상회하는 성능을 보임에 따라 다른 많은 오픈소스 모델에서도 MoE 방법론을 채택하기 시작했습니다.

본 포스트에서는 Mixtral 논문과 논문에서 다루고 있는 MoE 관련 개념을 다루도록 하겠습니다.
MoE(Mixture of Experts)
*MoE 개념은 1991년에 처음 제시되었고 SVM, LSTM등의 고전적(?)인 기법에 먼저 사용되었으나 본 포스트에서는 트랜스포머 구조에서 적용되는 MoE를 위주로 다루겠습니다.
- Dense VS Sparse Expert
일반적인 Dense 트랜스포머 구조(왼쪽)에서는 토큰이 입력된 후 셀프 어텐션 연산을 거치고 나서 똑같은 FFN(Feed Forward network)으로 전달됩니다. 반면 Sparse Expert 모델 구조에서는 각 토큰이 다른 FFN으로 라우팅되어 연산됩니다. 여기서 각각의 FFN을 Expert라고 정의합니다. 이와 같은 구조를 적용하게 되면 Dense Model과 비교해서 연산량은 유사하지만, 각 토큰에 대해 더 특화된 파라미터(unique parameter)를 적용하여 성능을 향상시킬 수 있습니다. 이와 같은 과정은 학습, 추론 두 단계에서 모두 적용됩니다.
- 라우팅 알고리즘과 Top-K 라우팅
라우팅 알고리즘이란 주어진 토큰을 어느 expert에 보내는지 결정하는 것을 의미하고, 이를 위해 학습 가능한 레이어가 이 과정을 담당합니다. 이것을 라우터(Router) 혹은 게이트 레이어(Gate Layer)라고 부릅니다.
라우터는 각 Expert당 하나의 벡터 값으로 이루어져 있으며, 토큰 입력이 들어오면 토큰의 임베딩 벡터와 각 expert를 담당하는 벡터의 합성곱(dot product)을 계산한 후(그림에서 Router Scores부분), 소프트맥스 함수를 통해 어느 expert를 사용할 지 결정하게 됩니다. (그림에서 Nomalized Router Scores 부분)
토큰을 몇 개의 expert에 라우팅하는지에 따라 Top-K 라우팅 알고리즘이라고 칭합니다. Top-1 라우팅의 경우 라우터 스코어가 가장 높은 expert에게 할당하고, Top-2 라우팅은 높은 점수 순으로 2개의 expert에게 토큰을 보내고 각 레이어를 통과한 값들이 가중합되어 다음 레이어로 보내게 됩니다.
이외에도 다양한 라우팅 알고리즘이 존재하지만 본 포스트에서 다루고 있는 Mixtral은 Top-2 라우팅 알고리즘을 채택하였으므로 여기서는 다루지 않겠습니다.
- MoE 모델의 특징
MoE 구조로 이루어진 모델은 다음과 같은 특징들을 지닙니다.
1. 같은 파라미터를 가진 Dense 모델과 비교해서 훈련과 추론 과정에서 적은 파라미터를 사용하며 그만큼 속도가 더 빠르고, 비용 측면에서 효율적입니다.
2. 많은 개수의 GPU/TPU 를 가지고 모델을 학습/추론할 때, 데이터 분산을 활용할 때 더욱 효과적입니다.
3. (dense 모델과 비교하여) 학습 과정이 불안정할 때가 있습니다.
4. (dense 모델과 비교하여) 새로운 도메인에 맞추어 파인 튜닝 되었을 때 성능이 떨어질 때가 있습니다.
Mixtral 8x7B
Mixtral 8x7B는 Mistral 7B의 구조를 기준으로 8개의 expert(FFN Block)을 사용하는 MoE 모델입니다.
라우팅 알고리즘으로는 Top-2 라우팅을 채택하였으며, 기존 트랜스포머 구조의 FFN Sub-block을 8개의 SwiGLU sub-block 구조의 expert로 대체하였습니다.
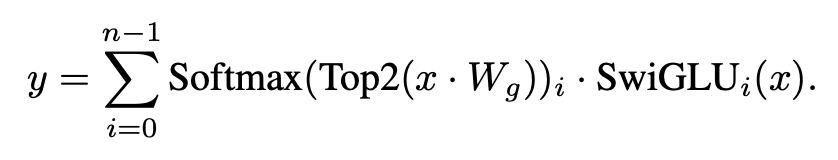
위 수식은 n개의 expert로 이루어진 MixTral 구조의 토큰 x에 대한 출력값 y 계산 수식입니다.
각 expert에 대한 routing score를 계산하고 소프트맥스함수를 거친 값이 Top 2안에 든다면 점수를 반영하여 expert에게 넘어가고, 그렇지 않다면 무시됩니다.
코드 형식으로 살펴보면 다음과 같습니다.
import dataclasses
from typing import List
import torch
import torch.nn.functional as F
from simple_parsing.helpers import Serializable
from torch import nn
@dataclasses.dataclass
class MoeArgs(Serializable):
num_experts: int
num_experts_per_tok: int
class MoeLayer(nn.Module):
def __init__(self, experts: List[nn.Module], gate: nn.Module, moe_args: MoeArgs):
super().__init__()
assert len(experts) > 0
self.experts = nn.ModuleList(experts)
self.gate = gate
self.args = moe_args
def forward(self, inputs: torch.Tensor):
# Step 1 : Expert로 보내기 위한 gate linear layer 통과
gate_logits = self.gate(inputs)
# Step 2 : gate logits에 대해 Top-K개 Expert 뽑기
weights, selected_experts = torch.topk(gate_logits, self.args.num_experts_per_tok)
# Step 3 : Top-K개의 experts에 대한 weights 구하기 (by softmax)
weights = F.softmax(weights, dim=1, dtype=torch.float).to(inputs.dtype)
results = torch.zeros_like(inputs)
# N개의 experts 돌면서 순회
for i, expert in enumerate(self.experts):
# Step 4 : i_th expert에 해당하는 tokens 뽑기
batch_idx, nth_expert = torch.where(selected_experts == i)
# Step 5 : i_th expert에 해당하는 token들 i_th expert에 통과
# Step 6 : 통과된 결과값에 expert weight 반영
results[batch_idx] += weights[batch_idx, nth_expert, None] * expert(
inputs[batch_idx]
)
return results원본 코드 : 미스트랄 깃허브
주석 : 김수환님 블로그
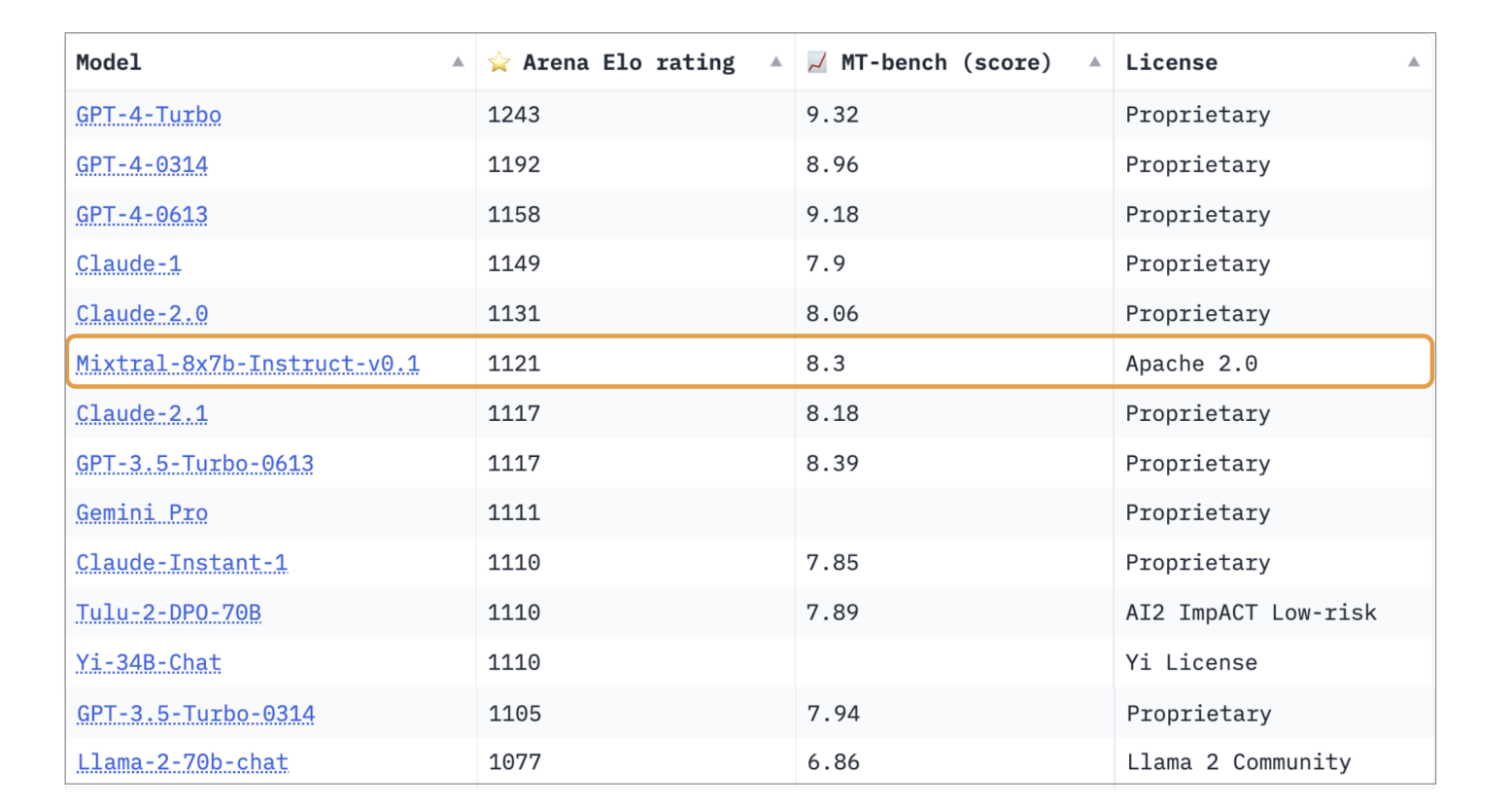
사전학습된 Mixtral을 Instruction+Feedback 데이터셋과 DPO 방법으로 파인튜닝한 Mixtral-Instruct는 mixtral 논문 작성일 기준으로 가중치가 공개된 LLM 중 MT-Bench에서 가장 높은 성능을 보여주었습니다.
(포스트 작성 시점에서는 mistral사의 새 모델인 mistral-medium 모델보다 뒤처지지만, API based 모델이므로 여전히 open weight 중에서는 가장 높은 점수입니다.)
- 라우팅 분석
Mixtral 연구진들은 각각의 expert가 도메인별로(수학, 생물학, 철학 등) 특화되어있는지를 검증하기 위해 Pile 데이터셋을 활용해 실험했습니다.
실험 결과, 라우터들이 각각의 expert에게 토큰을 할당하는 패턴이 arxiv 논문 문서들,생물학 문서들(PubMed), 철학 문서들(PhilPapers)에서는 굉장히 유사하게 나타나는 반면, 수학 도메인 문서에서는 다른 분포를 가지는 것을 확인할 수 있었습니다.

그러나 코드, 수학문제, 자연어 구문 등의 다양한 도메인의 토큰이 어느 expert에게 할당되는지를 분석한 결과 각각의 expert들이 선택되는 기준은 도메인 그 자체보다는 문서에서 각 토큰이 가지는 구문적 성질에 더 좌우받는다는 것을 관측할 수 있었습니다. 그리고 이러한 현상은 입력과 출력에 깊게 관여받는 첫 번째 레이어와 마지막 레이어에서 더욱 두드러지게 나타났습니다.
Refernce
A REVIEW OF SPARSE EXPERT MODELS IN DEEP LEARNING 논문
참고
'자연어처리' 카테고리의 다른 글
| [NLP] PROMETHEUS: INDUCING FINE-GRAINEDEVALUATION CAPABILITY IN LANGUAGE MODELS 논문 간단 리뷰 (0) | 2024.04.10 |
|---|---|
| [NLP]FLASK: FINE-GRAINED LANGUAGE MODELEVALUATION BASED ON ALIGNMENT SKILL SETS 논문 리뷰 (0) | 2024.03.25 |
| [NLP]OPENCHAT: ADVANCING OPEN-SOURCE LANGUAGEMODELS WITH MIXED-QUALITY DATA 논문 리뷰 (0) | 2023.11.09 |
| [NLP]한국어 거대모델(LLM)들 소개 (23년 5월) (2) | 2023.05.04 |
| [Hugging Face] PEFT에 대해 알아보자 (3) | 2023.02.16 |