
들어가며

지난 9월 11일 업스테이지에서 solar-pro-preview, solar-pro-preview-instruct 가 오픈소스 모델로 출시되었습니다. 업스테이지에서 처음으로 공개했던 모델 SOLAR 10.7B보다 2배 이상 큰 파라미터 수를 가지고 있으며, 단일 GPU에서 효율적으로 실행할 수 있다고 합니다. 본 포스트에서는 solar-pro-preview 모델의 특징에 대해 살펴보겠습니다.
Spec
solar-pro-preview 모델의 간략한 스펙은 다음과 같습니다.
| # params | 22.1B |
| context window | 4k |
| 지원 언어 | en |
context window가 최근 출시되는 다른 오픈소스 모델에 비해 꽤나 짧다는 점과, 지원 언어가 영어 한 가지라는 점이 눈에 띄네요.
이 두 가지 사항 모두 solar pro 정식 출시할 때 개선해서 나온다고 하니 기대해 봐야 할 것 같습니다.
모델링 코드 살펴보기

기존 solar 10.7B는 transformers 라이브러리의 LlamaForCausalLM 구조를 채택하고 있기에, vllm을 포함한 다양한 서빙 라이브러리에서 문제 없이 동작했습니다.

그러나 이번에 출시된 solar-pro-preview 모델에서는 기존 transformers 라이브러리의 모델 클래스를 사용하지 않고, SolarForCausalLM이라는 새로운 아키텍쳐를 사용합니다. 따라서
model = AutoModelForCausalLM.from_pretrained(
"upstage/solar-pro-preview-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)와 같이 모델을 사용할 때 trust_remote_code=True 라는 부분을 꼭 지정을 해줘야 하죠.
그렇다면 SolarForCausalLM 아키텍처는 다른 transformers의 LLM 아키텍처에 비해 어떤 점이 달라졌을까요?
사용자 지정 아키텍처를 사용하는 모델은 modeling_{model_name}.py 에 해당 모델의 아키텍처를 정의해서 사용합니다.
solar-pro-preview 모델의 아키텍처 또한 허깅페이스 repo의 modeling_solar.py 에 정의되어 있고, 각종 config 들은 configuration_solar.py에서 불러와 사용하는 구조입니다.
먼저 solar의 model config를 살펴보면, 대부분은 llama나 mistral과 비슷한 구조를 가지나, 한 가지 추가된 사항이 있습니다.

SolarConfig라는 클래스를 초기화할 때, bskcn이라는 리스트 형태의 변수를 선언하는 것을 확인할 수 있습니다. 1~4번까지는 정수의 리스트, bskcn_tv 에는 0.9와 0.8이 들어있는 리스트 형태입니다. 이 값들이 어디에서 쓰이는 지 확인해 보겠습니다.
# modeling_solar.py line 1051~
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
next_decoder_cache = None
bskcn_1 = None
bskcn_2 = None
bskcn_tv = self.config.bskcn_tv[0] if self.training else self.config.bskcn_tv[1]
for layer_idx, decoder_layer in enumerate(self.layers):
if layer_idx in self.config.bskcn_1:
bskcn_1 = hidden_states
if layer_idx in self.config.bskcn_2:
bskcn_2 = hidden_states
if layer_idx in self.config.bskcn_3:
hidden_states = (bskcn_1*bskcn_tv).to(hidden_states.device) + hidden_states*(1-bskcn_tv)
if layer_idx in self.config.bskcn_4:
hidden_states = (bskcn_2*bskcn_tv).to(hidden_states.device) + hidden_states*(1-bskcn_tv)
위 코드는 solar 모델의 decoder 부분 forward 함수의 일부분입니다.
코드를 살펴보면 다음과 같은 로직이 적용되어있는 것을 확인할 수 있습니다.
- bskcn_1: 12, 20, 32, 44번째 레이어에서 hidden states를 저장
- bskcn_2: 20, 32번째 레이어에서 hidden states를 저장
- bskcn_3: 16, 24, 36, 48번째 레이어에서 bskcn_1의 hidden states를 현재 hidden states와 결합
- bskcn_4: 28, 40번째 레이어에서 bskcn_2의 hidden states를 현재 hidden states와 결합
위에서 선언되었던
- bskcn_1,3 리스트는 hidden states를 저장할 리스트 인덱스
- bskcn_2,4 리스트는 미리 저장했던 hidden states와 현재 인덱스의 hideen state를 결합하는 인덱스
- bskcn_tv는 결합할 때의 가중치
가 되겠네요.
이 때, 모델이 훈련 중이라면 가중치를 0.9, 추론 중이라면 0.8으로 각각 다르게 설정한 부분까지 확인할 수 있습니다.

이 구조를 claude에게 주고 시각화 해달라고 하니 이런 다이어그램이 나왔네요. 이해가 잘 가시나요?
이러한 구조는
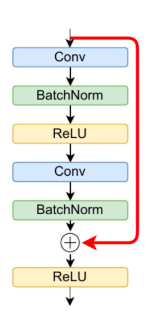
ResNet 등의 모델에서 사용하고 있는 skip connection기법 을 레이어 단위로, 가중치를 적용해서 하는 것이라고 할 수 있겠네요. LLM에서 이러한 모델 구조를 사용하는 것은 처음 본 것 같은데, 혹시 아니라면 댓글로 알려주시면 감사하겠습니다 ㅎㅎ
+
그리고 현재 공개된 solar-pro-preview의 hidden_layer 수는 32지만, bskcn 인덱스 리스트에는 32를 초과하는 36,40,48 등의 수도 있는 것을 확인할 수 있습니다. 이는 아마도 더 큰 모델(아마도 API 전용)을 위한 config가 아닐까 생각됩니다.🤫
한국어는 어느정도 할까?
solar-pro-preview- 의 공식 지원 언어는 영어 하나뿐이지만, 그래도 한국 기업에서 만든 모델이어서 solar-pro-preview-instruct에 한국어 인스트럭트 벤치마크 Logickor 테스트를 돌려보았습니다.



애초부터 영어만 지원하는 모델이었기 때문에 Logickor 리더보드 상위 모델들과는 점수 차이가 많이 나는 모습이지만,
예시를 1개 제공하는 것만으로도 점수가 크게 오르는 것(5.75->6.55)을 보아 모델 자체의 추론 능력이 상당하다는 것을 확인할 수 있었습니다.
마치며
최근 exaone이나 solar와 같이 한국 기업에서 자체적으로 개발한 언어 모델을 오픈 소스로 공개하는 일들이 많아지고 있어 정말 흥미진진한데요, 이에 자극을 받아 더욱 다양한 IT 기업에서 자체 언어 모델을 제작고 배포하는 일이 많아졌으면 하는 마음입니다.
읽어주셔서 감사합니다!