
Knowledge Distillation(지식 증류)란?
Knowledge Distillation(이하 KD)는 Teacher Network에서 얻어낸 지식을 Student Network로 전달시켜 학습하는 기법이다.
처음 이 방법이 제안되었을 때에는 큰 모델에서 학습한 지식을 작은 모델로 전달함으로써 모바일 기기 등 연산능력이 강력하지 않은 하드웨어에서도 딥러닝 모델을 동작시키려는 목적이었다.
최근에는 지속적으로 들어오는 데이터 스트림을 학습하기 위한 Continual Learning 방법론 중 하나로 KD가 대두되고 있는데, 이전 시점의 모델이 학습한 지식(Hidden Knowledge)를 현재 시점 모델에게 주입하는 방식으로 모델에게 새로운 지식을 학습시킨다.
본 포스팅에서는 언어 모델의 Continual Learning을 효과적으로 하기 위해 여러 학습방법을 적용해 실험한 논문 'Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora' 에서 제시한 4가지 KD기법에 대해 알아볼 것이다.
4가지 방법 모두 이전 시점 모델과 현재 시점 모델에서 발생하는 Distillation Loss를 줄이는 방식으로 학습시키는 것에 유의하자.
1. Logit distillation
Logit distillation은 KD가 처음 등장한 논문 'Knowledge Distillation in Neural Network'에서 사용한 방법이다.
이전 시점 모델의 결과 로짓값과 현재 시점 모델의 결과 로짓값을 쿨백 라이블러 발산(Kullback-Leibler Divergence)에 투입하여 두 로짓값의 분포가 점점 닮아지도록 하는 방식이다.
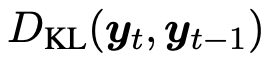
Knowledge Distillation in Neural Network 논문 https://arxiv.org/pdf/1503.02531.pdf
KLD 설명 블로그 https://daebaq27.tistory.com/88
2. representation distillation
MLM추론 전 단계에서 각 단어의 hidden representation을 추출하여 이전 시점 모델의 representation과 현재 시점 representation 사이의 편차를 줄이는 MSE Loss function으로 사용했다.
이 방식은 Patient Knowledge Distillation(2019)과 TinyBERT(2020)에서 사용되었으며, transformer layer 단계에서 attention weight가 구문, 상호참조 정보 등의 언어학적인 정보까지 담고있기 때문에 가능하다.

Patient KD 논문 https://aclanthology.org/D19-1441.pdf
TinyBERT 논문https://aclanthology.org/2020.findings-emnlp.372.pdf
3. contrasive distillation
contrasive distillation은 비지도학습 기법 중 하나인 contrasive learning을 KD에 적용시킨 방법으로, Co2L: Contrastive Continual Learning(2022)에서 처음 제시되었다.
이전 시점과 현재 시점의 SImCSE 계산값사이의 dot-product similarity matrix를 각각 계산하고, 각 matrix의 cross-entropy를 loss로 사용한다.
-SimCSE란?-
문장 임베딩에서 사용되는 contrasive learning framework이다. input sentence를 dropout을 2번 적용해 positive pair로 정의하고, 같은 batch내의 다른 문장을 negative로 정의해 contrasive learning을 할 수 있도록 한다.


Co2L: Contrastive Continual Learning 논문
https://arxiv.org/pdf/2106.14413.pdf
SimCSE 논문
https://arxiv.org/pdf/2104.08821.pdf
설명 블로그
4. self-supervised distillation
self-supervised distillation은 SEED: Self-supervised distillation for visual representation(2021)에서 제안한 KD기법이다.
위에서 설명한 contrasive distillation과 유사하지만, 위에서는 배치 내의 문장 사이의 유사도를 기반으로 학습했던것과 달리 유사도 계산이 batch전체와 larger example 사이에서 이루어진다는 차이가 있다. 이를 통해 더 풍부한 정보를 distill할 수 있다는 장점이 있다.
'Lifelong Pretraining...' 논문에서는 SEED 방법을 logit distillation과 결합한 SEED-logit distillation 방법 또한 채용해 사용하였다.
SEED 논문 https://arxiv.org/pdf/2101.04731.pdf
결론
'Lifelong Pretraining...' 논문에서는 대체적으로 다른 continual learning 기법들보다 KD를 사용한 기법들이 성능이 좋지만, 상당히 task-dependent하며, 실험 결과 대체적으로 가장 좋은 성능을 보여주었던 방법은 SEED-logit KD였기 때문에, 비교적 고전적인 방법인 logit-KD방법을 능가하는 방법이 요구된다고 결론지었다.
'자연어처리' 카테고리의 다른 글
| [NLP]한국어 거대모델(LLM)들 소개 (23년 5월) (2) | 2023.05.04 |
|---|---|
| [Hugging Face] PEFT에 대해 알아보자 (3) | 2023.02.16 |
| [NLP] Lexical Simplification(어휘 단순화) (0) | 2023.02.11 |
| [NLP]Word Sense Induction(단어 의미 추론) (0) | 2023.02.06 |
| [워드 임베딩] Glove : Gloval Vectors for word Representation (2) | 2023.01.20 |