
논문 pdf 링크 :
https://nlp.stanford.edu/pubs/glove.pdf
* 본 논문은 2014년 EMNLP학회에 제출되었으며, 워드 임베딩 방법론인 Glove를 다루고 있습니다.
* 본 포스트는 2022년 9월 6일 자연어처리 논문 스터디에서 작성자가 발표한 내용을 재구성해 작성했습니다.
본문을 읽기 위해 필요한 지식들
워드 임베딩 :
word2vec :
기존 워드 임베딩 방법론들의 한계

본 논문이 발표되기 이전에 워드 임베딩에서 주요한 방법론은 크게 2가지가 있었습니다.
먼저 LSA(Latent Semantic Analysis) 는 문서에서 각 단어의 빈도를 행렬화한 뒤 그것을 차원축소하여 코사인 유사도 기반으로 의미를 찾아내는 방법이었고,
워드투벡터(Word2Vec)은 주변에 있는 단어로 중심단어를 예측하거나(CBOW) 중심단어로 주변 단어를 예측하는(Skip-Gram) 방법으로 손실 함수를 통해 학습하는 방법이었습니다.
각 방법론에는 단점이 있었는데, LSA의 경우 단어 의미 유추(Analogy Task)에 성능이 떨어진다는 단점이 있었습니다.
- Analogy Task 란? -> 한국 : 일본 = 서울 : ? 에서 ? 에 들어갈 단어를 찾는 작업
반면 Word2Vec은 윈도우 크기 내에서만 학습이 이루어지기 때문에 문서의 전체적인 통계를 반영하지 못한다는 단점이 있었습니다.
글로브(Glove)는 이 두 가지 방법론의 단점을 극복하면서 Wordvec의 예측 기반 방법과 LSA의 통계(행렬) 기반 방법론을 동시에 사용하고자 했습니다.
이를 구현하기 위한 핵심 아이디어는
이는 임베딩 된 중심 단어와 주변 단어 벡터의 내적(유사도)이 전체 문서에서의 동시 등장 확률이 되도록 만드는(근사시키는) 것 이고,
다음과 같은 수식으로 나타낼 수 있습니다.

동시 등장 행렬과 동시 등장 확률
중심 단어와 주변 단어의 내적값, 즉 유사도는 워드투벡터에서 이미 다룬 개념이지만,
동시 등장 확률을 다루기 위해서는 먼저 동시 등장 행렬에 관해 알 필요가 있습니다.
동시 등장 행렬은 i 단어의 윈도우 크기 내에서 k단어가 등장한 횟수를 i행 k열에 기재한 행렬입니다.
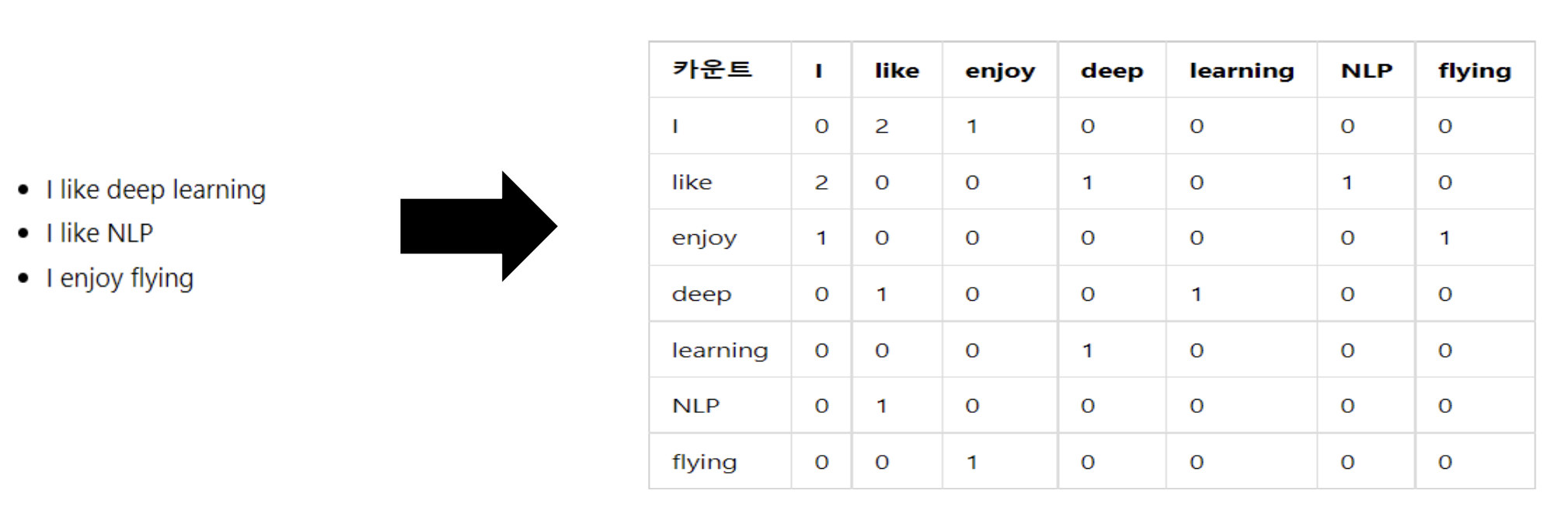
동시 등장 확률은 동시 등장 행렬에서 특정 단어의 전체 등장 횟수를 세고, 그 단어가 등장했을 때 주변 단어가 등장할 조건부 확률 입니다.

위의 표를 통해 중심 단어에 따른 동시 등장 확률의 차이를 볼 수 있는데,
중심 단어가 'ice'일 때에는 'water'라는 단어가 등장할 확률이 가장 높고, 'fashion'이라는 단어가 등장할 확률이 가장 낮습니다.
맨 아랫줄을 보시면 중심 단어가 'solid'일 때 'ice'에 대한 동시 등장 확률이 'steam'에 대한 동시 등장 확률보다 높기 때문에 확률의 비율이 8.9인 반면, 중심 단어가 'gas'일 때에는 'steam'이 등장할 확률이 훨씬 높아지기 때문에 비율이 0.085로 줄어든 것을 확인할 수 있습니다.
손실함수 만들기
위에서 언급했다시피, Glove의 핵심 아이디어는 '중심 단어와 주변 단어의 내적값과 전체 말뭉치에서의 동시 등장 확률을 같게 하는 것' 입니다.

이를 수식으로 하면 위와 같습니다.
하지만 여기서 짚고 넘어가야할 중요한 사실은, 학습을 시킬 때 중심 단어와 주변 단어는 무작위로 정해지기 때문에 중심 단어와 주변 단어가 서로 바뀌어도 값은 똑같아야 한다는 것입니다.
이를 만족하는 함수중 하나가 지수 함수(Exponential function)이고, 이를 함수 F 자리에 넣을 수 있습니다.

여기에 양변에 로그를 취하고, 중심 단어와 주변 단어를 바꿔도 식이 성립하기 위해 wi와 wk에 대한 편향을 각각 추가합니다.

일반화시키면 손실함수는 다음과 같습니다.

하지만, 동시 등장 행렬 X는 희소 행렬(sparse matrix)일 가능성이 높기 때문에, 동시 등장 확률 또한 굉장히 낮은 값일 확률이 높고 이는 학습에 도움이 되지 않습니다.
이와 같은 현상을 방지하기 위해 다음과 같은 가중치 함수(weighting function)을 손실함수에 도입하였습니다.

동시 등장 빈도의 값이 작으면 함수의 값은 작아지지만, 값이 지나치게 높아도 1 이상의 값을 갖지 않는 가중치 함수를 손실함수에 곱해줌으로써 가중치의 역할을 할 수 있도록 했습니다.
최종적인 손실함수는 다음과 같습니다.

실험 결과
실험 결과 Glove는 word analogy task, word similarity task, NER task에서 기존 워드 임베딩 방법보다 높은 성능을 보였습니다.

또한 같은 조건 하에서 Word2Vec보다 짧은 훈련 시간을 기록했습니다.

모델 분석
말뭉치 전체의 통계 정보를 고려하기는 했지만 동시 등장 확률을 계산하는 과정에서 window size(전후로 몇 개의 단어를 계산할지)는 여전히 사용됩니다.
윈도우 사이즈에 따라서 높은 성능을 보이는 task의 종류가 달랐습니다.
- window size가 작고 window가 비대칭적일 경우 문법적인(syntactic) task에서 성능이 더 높았습니다.
- window size가 클 경우 의미론적인(sementic) task에서 성능이 더 높았습니다.
'자연어처리' 카테고리의 다른 글
| [NLP]한국어 거대모델(LLM)들 소개 (23년 5월) (2) | 2023.05.04 |
|---|---|
| [Hugging Face] PEFT에 대해 알아보자 (3) | 2023.02.16 |
| [NLP] Lexical Simplification(어휘 단순화) (0) | 2023.02.11 |
| [NLP]Word Sense Induction(단어 의미 추론) (0) | 2023.02.06 |
| [Continual Learning] Knowledge Distillation 기법 정리 (0) | 2023.01.30 |